
—— More data usually beats better algorithms. ——
A Brief History of Apache Hadoop
Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open source web search engine, itself a part of the Lucene project.
Nutch was started in 2002 whose architecture wouldn’t scale to the billions of pages on the Web. In 2003, Google published a paper that described the architecture of Google’s distributed filesystem, called GFS, which would solve their storage needs for the very large files generated as a part of the web crawl and indexing process. In 2004, Nutch’s developers set about writing an open source implementation, the Nutch Distributed Filesystem (NDFS). In 2004, Google published another paper that introduced MapReduce to the world. Early in 2005, the Nutch developers had a working MapReduce implementation in Nutch, and by the middle of that year all the major Nutch algorithms had been ported to run using MapReduce and NDFS.
NDFS and the MapReduce implementation in Nutch were applicable beyond the realm of search, and in February 2006 they moved out of Nutch to form an independent subproject of Lucene called Hadoop. At around the same time, Doug Cutting joined Yahoo!, which provided a dedicated team and the resources to turn Hadoop into a system that ran at web scale. This was demonstrated in February 2008 when Yahoo! announced that its production search index was being generated by a 10,000-core Hadoop cluster. In January 2008, Hadoop was made its own top-level project at Apache, confirming its success and its diverse, active community.
Today, Hadoop is widely used in mainstream enterprises. Hadoop’s role as a general purpose storage and analysis platform for big data has been recognized by the industry. Commercial Hadoop support is available from large, established enterprise vendors, including EMC, IBM, Microsoft, and Oracle, as well as from specialist Hadoop companies such as Cloudera, Hortonworks, and MapR.
Apache Hadoop Ecosystem
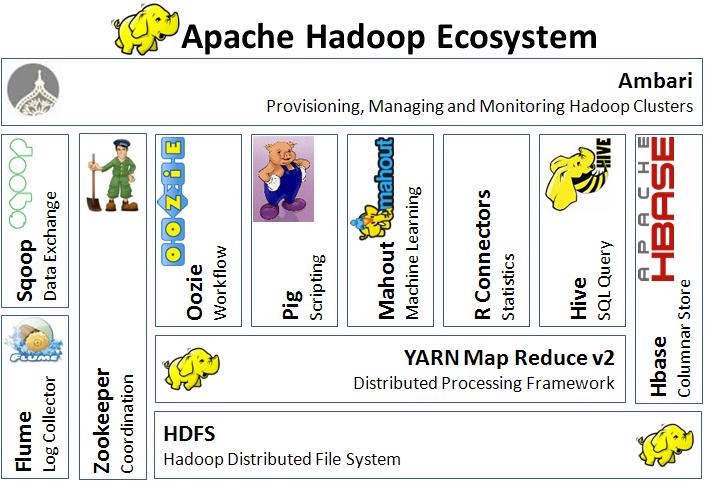
Data Storage and Analysis
Although the storage capacities of hard drives have increased massively over the years, access speeds - the rate at which data can be read from drives - have not kept up. One typical drive from 1990 could store 1370 MB of data and had a transfer speed of 4.4 MB/s, so you could read all the data from a full drive in aroud five minutes. Over 20 years later, 1-terabyte drives are the norm, but the transfer speed is around 100 MB/s, so it takes more than two and a half hours to read all the data oof the disk.
MapReduce provides a programming model that abstracts the problem from disk reads and writes, transforming it into a computation over sets of keys and values.
MapReduce is a batch query processor, and the ability to run an ad hoc query against your whole dataset and get the results in a reasonable time is transformative. MapReduce is fundamentally a batch processing system, and is not suitable for interactive analysis.
Beyond Batch
The first component to provide online access was HBase, a key-value store that uses HDFS for its underlying storage. HBase provides both online read/write access of individual rows and batch operations for reading and writing data in bulk, making it a good solution for building applications on.
The real enabler for new processing models in Hadoop was the introduction of YARN (which stands for Yet Another Resource Negotiator) in Hadoop 2. YARN is a cluster resource management system, which allows any distributed program (not just MapReduce) to run on data in a Hadoop cluster. Here are examples:
- Interactive SQL: achive low-latency responses for SQL queries on large dataset sizes, Hive, Impala.
- Interactive Analytics at Scale: Druid
- Iterative processing: machine learning, Spark
- Streaming processing: Streaming systems like Storm, Spark Streaming make it possible to run realtime, distributed computations on unbounded streams of data and emit results to Hadoop storage or external systems.
- Search: Solr
Comparison with Other Systems
Relational Database Management Systems
Seek time is improving more slowly than transfer rate. Seeking is the process of moving the disk’s head to a particular place on the disk to read or write data. It characterizes the latency of a disk operation, whereas the transfer rate corresponds to a disk’s bandwidth.
If the data access pattern is dominated by seeks, it will take longer to read or write large portions of the dataset than streaming through it, which operates at the transfer rate. On the other hand, for updating a small proportion of records in a database, a traditional B-Tree (the data structure used in relational databases, which is limited by the rate at which it can perform seeks) works well. For updating the majority of a database, a B-Tree is less efficient than MapReduce, which uses Sort/Merge to rebuild the database. Difference between MapReduce and RDBMS:
- MapReduce is a good fit for problems that need to analyze the whole dataset in a batch fashion, particularly for ad hoc analysis.
- An RDBMS is good for point queries or updates, where the dataset has been indexed to deliver low-latency retrieval and update times of a relatively small amount of data.
MapReduce suits applications where the data is written once and read many times, whereas a relational database is good for datasets that continually updated.
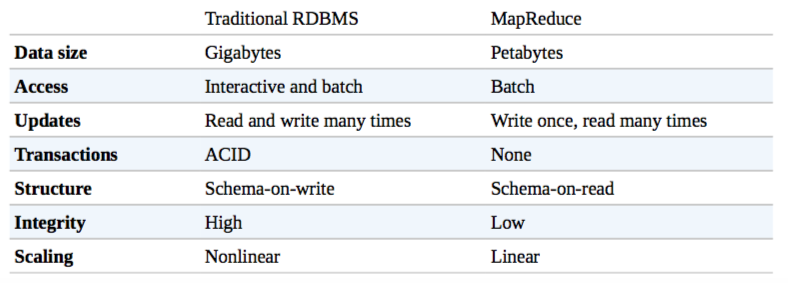
Another difference between Hadoop and an RDBMS is the amount of structure in the datasets on which they operate. There are three kinds of data:
- Structure data is organized into entities that have a defined format, such as XML documents or database tables that conform to a particular predefined schema.
- Semi-structure data is looser and though there may be a schema which may be used only as a guide to the structure of the data, for example JSON.
- Unstructured data does not have any particular internal structure, for example, image data.
Hadoop works well on unstructure of semi-structured data because it is designed to interpret the data at processing time (so called schema-on-read). This provides flexibility and avoids the costly data loading phase of an RDBMS, since in Hadoop it is just a file copy.
High-performance computing or Grid Computing
HPC is to distribute the work across a cluster of machines, which access a shared filesystem, hosted by a storage area network (SAN). This works well for predominantly compute-intensive jobs, but it becomes a problem when nodes need to access larger data volumes and the network bandwidth will be the bottleneck and compute nodes become idle.
Hadoop tries to co-locate the data wih the compute nodes, so data access is fast because it is local. This feature, known as data locality, is at the heart of data processing in Hadoop and is the reason for its good performance.
Distributed processing frameworks like MapReduce spare the programmer from having to think about failure, since the implementation detects failed tasks and reschedules replacements on machines that are healthy. MapReduce is able to do this because it is a shared-nothing architecture, meaning that tasks have no dependence on the other. By contrast, Message Passing Interface (MPI) programs have to explicitly manage their own checkpointing and recovery, which gives more control to the programmer but makes them more difficult to write.