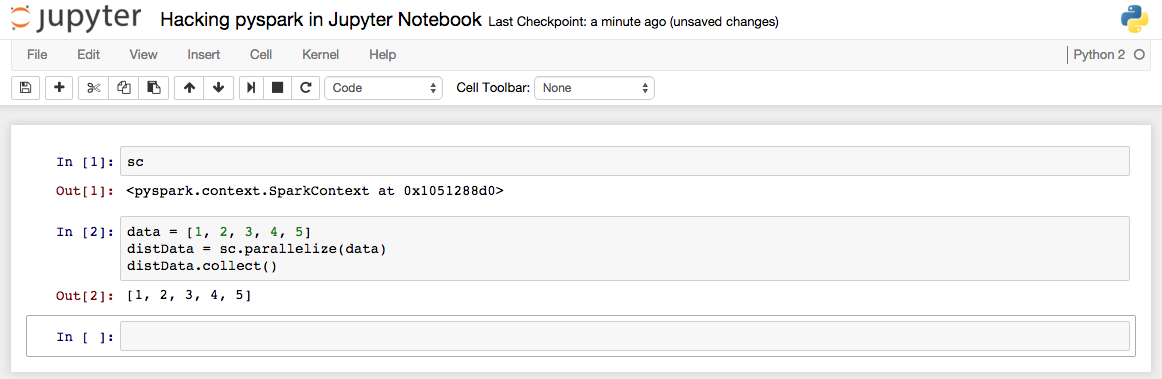
Python is a wonderful programming language for data analytics. Normally, I prefer to write python codes inside Jupyter Notebook (previous known as IPython), because it allows us to create and share documents that contain live code, equations, visualizations and explanatory text. Apache Spark is a fast and general engine for large-scale data processing. PySpark is the Python API for Spark. So it’s a good start point to write PySpark codes inside jupyter if you are interested in data science:
If you are a pythoner, I highly recommend installing Anaconda. Anaconda conveniently installs Python, the Jupyter Notebook, and other commonly used packages for scientific computing and data science. Go to https://www.continuum.io/downloads, find the instructions for downloading and installing Anaconda (jupyter will be included):