
Apache Spark is an open source cluster computing system that aims to make data analytics fast — both fast to run and fast to write.
BDAS, the Berkeley Data Analytics Stack, is an open source software stack that integrates software components being built by the AMPLab to make sense of Big Data.
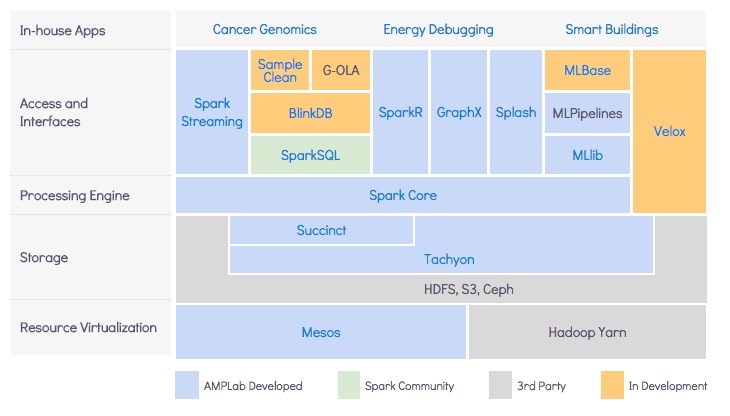
| Spark Components | VS. | Hadoop Components |
|---|---|---|
| Spark Core | <——> | Apache Hadoop MR |
| Spark Streaming | <——> | Apache Storm |
| Spark SQL | <——> | Apache Hive |
| Spark GraphX | <——> | MPI(taobao) |
| Spark MLlib | <——> | Apache Mahout |
==Why spark is fast:==
- in-memory computing
- Directed Acyclic Graph (DAG) engine, compiler can see the whole computing graph in advance so that it can optimize it. Delay Scheduling
Resilient Distributed Dataset
- A list of ==partitions==
- A ==function== for computing each split
- A list of ==dependencies== on other RDDs
- Optionally, a ==Partitioner== for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of ==preferred locations== to compute each split on (e.g. block locations for an HDFS file)
Storage Strategy
|
|
RDD, transformation & action
lazy evaluation

Lineage & Dependency & Fault Tolerance
Lineage
==Basic for spark fault tolerance==
Lineage Graph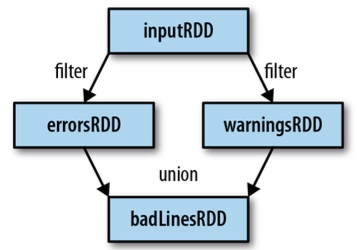
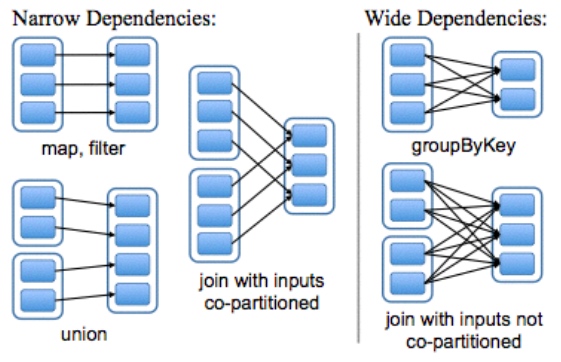
Dependency
Narrow Dependencies: one partition depends on one partition
- calculation can be done on single node.
Wide Dependencies: one partition depends on muliti partitions
- If one partition fails, all parent partitions need to be computed.
- should use rdd.persist to cache the middle outputs
Spark 1.0 updated
spark submit
history server (persistent UI)
spark-defaults.conf