Hadoop: The Definitive Guide, Fourth Edition: http://shop.oreilly.com/product/0636920033448.do
Code and Data: http://hadoopbook.com/code.html
Download ncdc weather dataset: https://gist.github.com/rehevkor5/2e407950ca687b36fc54

linbojin
右手Scala, 左手Go
No results found
右手scala,左手go
Practical Vim: Dot Formula
—— Dot Formula: One keystroke to move and one keystroke to execute. ——
Doc Command: repeat last changel
Install and Manage Node Versions with NVM
It’s very easy to install and manage multiple active node.js versions by Node Version Manager(NVM).
Install or update nvm
First you’ll need to make sure your system has a c++ compiler. For OSX, XCode will work. And then install or update nvm by the following command:
|
|
Getting Started with Vim by Vimtutor
———————- Vim: The God of Editors ———————-
This is a simple Vim Tutorial from vim built-in documents, you can get the whole vimtutor by typing vimtutor in shell or vimtutor -g for GUI version. It is intended to give a brief overview of the Vim editor, just enough to allow you to use the editor fairly easily.
Lesson 1: Text Editing Commands
|
|
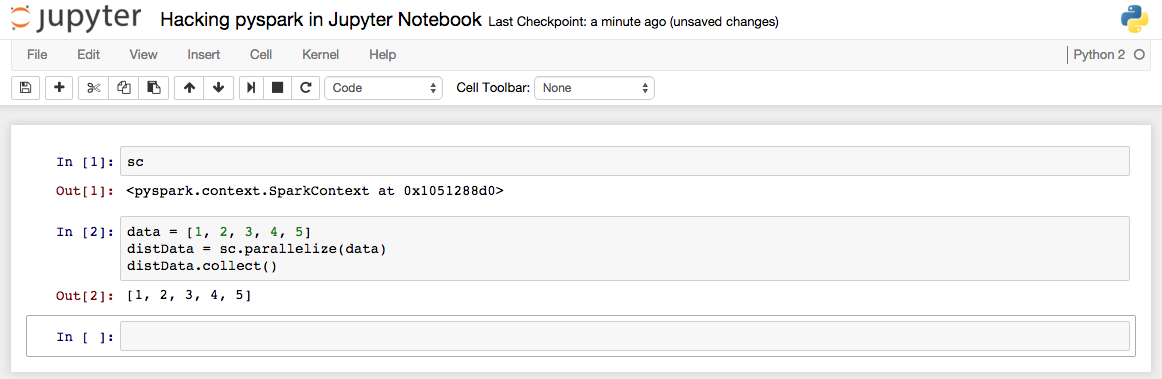
Hacking PySpark inside Jupyter Notebook
Python is a wonderful programming language for data analytics. Normally, I prefer to write python codes inside Jupyter Notebook (previous known as IPython), because it allows us to create and share documents that contain live code, equations, visualizations and explanatory text. Apache Spark is a fast and general engine for large-scale data processing. PySpark is the Python API for Spark. So it’s a good start point to write PySpark codes inside jupyter if you are interested in data science:
|
|
NPM Playbook
NPM (node package manager) is a package management tool for Node.js.
Node.js is an open source JavaScript runtime built on Chrome’s V8 JavaScript engine. Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient. Note that Node.js is a server side runtime environment rather than a language.
Initial project
package.json will be firstly created by npm init:
|
|
Books of 2016

Loopback API Framework
The LoopBack framework is a set of Node.js modules that you can use independently or together to quickly build applications that expose REST APIs.
Resources
Loopback: http://loopback.io/
Getting started: http://loopback.io/getting-started/
Create a simple API: https://docs.strongloop.com/display/public/LB/Create+a+simple+API
LoopBack core concepts: https://docs.strongloop.com/display/public/LB/LoopBack+core+concepts
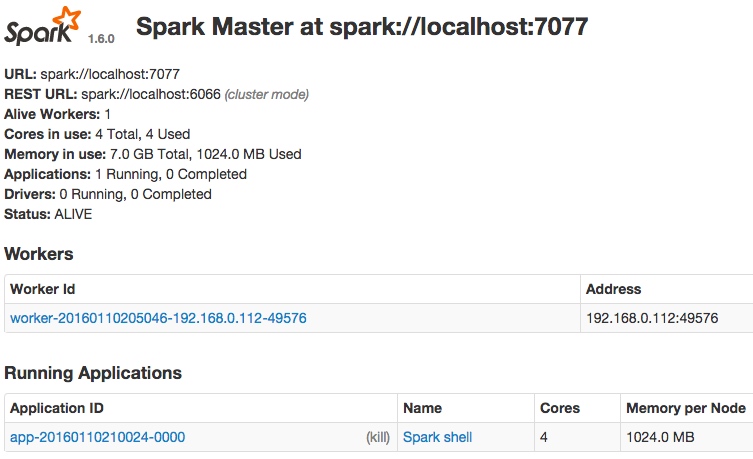
Spark Source Codes 01 Submit and Run Jobs
standalone mode
|
|
Start Master at 8080,
org.apache.spark.deploy.master.Master
onStart()
|
|
Start Worker at 8081
onStart() => registerWithMaster()
|
|
Start Spark-shell over cluster on http://localhost:4040
|
|
|
|
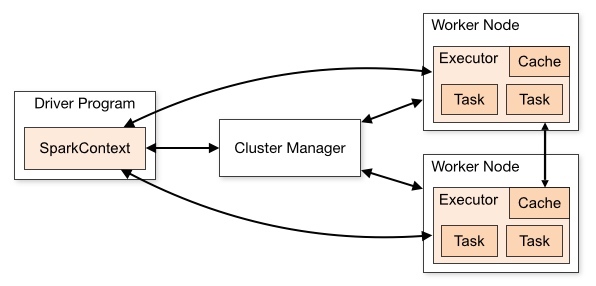
sc.textFile(“”)
RDD Object
DAGScheduler: error between stages
==TaskSet===>
TaskScheduler: error inside stage
org.apache.spark.scheduler.TaskScheduler
Reading Spark Souce Code in IntelliJ IDEA
It’s a good choice to read spark souce code in IntelliJ IDEA. This tutorial introduces how to do it.
Get spark repository
- Fork apache spark project to your Github account
Clone spark to local:
12$ git clone git@github.com:username/spark.git$ cd spark/